
Playwright scraper
Besides Playwright this script uses a ‘Webserver’ called Express. Install it with command ‘npm i express’ in the terminal.
Steps:
- create script (crawl.js) with Express and Playwright
- open terminal and start webserver with ‘node crawl’
- go to localhost:1234 in browser
- add parameter to url : ‘localhost:1234/crawl?website=https://domaintoscan.com’
- scope the scraping by filtering on url or just scrape all pages from the defined domain
- kick off the scraping action by just hitting enter after adding the url-parameter
- if you have headeless:false in the script you shoud see a browser opening
- the script will start scraping defined elements(seo-title, meta-data, headings, images, links)
- in the terminal window results of the scrape should be logged, so you can follow what has been found
- Playwright will add links found to the queue.
- Every url will be scraped
- Urls which do not start with the domainname used in the parameter are excluded from scrapeing
- Urls ending with ‘.pdf’ will be excluded
- Urls with a ’#’, ’@’, ’?’ and ‘tel:’ will be excluded
create crawl.js. This script starts the webserver and scrapes data from urls.
// Go to localhost:1234/crawl?website=
// Add the url you want to scrape as parameter
// http://localhost:1234/crawl?website=https://www.essent.nl
// http://localhost:1234/crawl?website=http://books.toscrape.com/
const playwright = require('playwright-chromium');
const express = require('express');
const app = express();
const port = 1234;
app.get("/crawl", async(req, res, next) => {
const website = req.query.website
if (!website) {
const err = new Error("required parameter missing");
err.status = 400
next(err);
}
try {
var startTime = new Date();
console.log('Start time', startTime)
const browser = await playwright.chromium.launch({ headless: true });
// const browser = await playwright.chromium.launch({ headless: false, slowMo: 250 });
const context = await browser.newContext({
// viewport: { width: 1240, height: 800 },
// deviceScaleFactor: 1,
// recordVideo: { dir: 'videos/' }
});
// await context.addCookies([...cookiesArr])
const registry = {};
let queue = [website]
// const addCount = 0
let addCount = 0
while (queue.length > 0) {
const url = queue[queue.length - 1];
console.log("Current url:", url)
const page = await context.newPage();
// const page = await browser.newPage();
await page.goto(url);
registry[url] = []
try {
addCount = addCount += 1
console.log('COUNTER', addCount)
registry[url].push({
'url': url,
'id': addCount
});
// return addCount;
} catch {
}
// registry[url] = await page.content() // Does work, gets whole content of the page.
try {
const htmlTitle = await (await page.$('title').textContent().trim());
console.log('Htmltitle:', htmlTitle)
if (htmlTitle.length > 0)
registry[url].push({
'metaElement': 'html-seo-title',
'pageTitle': htmlTitle || 'Empty page title'
})
else {
registry[url].push({
'metaElement': 'html-seo-title',
'pageTitle': 'Empty page title'
})
}
} catch (error) {
console.log('html-title not found')
registry[url].push({
'metaElement': 'html-seo-title',
'pageTitle': 'No htmlTitle'
})
}
// Check Canonical url
try {
const canon = await page.$$("link[rel='canonical']")
for (i = 0; i < canon.length; i++) {
const canonUrl = await canon[i].getAttribute('href')
if (canonUrl) {
console.log('canonical url:', canonUrl)
registry[url].push({
'metaElement': 'canonical-url',
'id': i,
'canonicalUrl': canonUrl
})
} else {
console.log('canonical empty / not found')
registry[url].push({
'metaElement': 'canonical-url',
'id': 'i',
'canonicalUrl': 'there is no canonical url in the html - no canonurl'
})
}
}
} catch {
console.log('canonical not found')
registry[url].push({
'metaElement': 'canonical-url',
'canonicalUrl': 'there is no canonical url in the html'
})
}
// End Canonical url
////////// start meta-data
try {
const metas = await page.$$('meta')
// console.log('Metas:', metas)
for (i = 0; i < metas.length; i++) {
const metaType = await metas[i].getAttribute('name');
const metaContent = await metas[i].getAttribute('content');
const metaProp = await metas[i].getAttribute('property');
// console.log('metas:', metaType + ' ' + metaContent + ' ' + metaProp)
registry[url].push({
'metaElement': metaType,
'id': i,
'metaElementContent': metaContent,
'metaElementProperty': metaProp
})
}
} catch {
registry[url].push({
'metaElement': 'No metaType',
'id': 'i',
'metaElementContent': 'NometaContent',
'metaElementProperty': 'NometaProp'
})
}
// End Meta
// start Headings
try {
// registry[url] = await page.locator("H3").textContent(); // Works
const headIngs = await page.$$("h1, h2, h3, h4, h5, h6");
// headingDetails = []
// console.log('Headings:', headIngs)
for (let i = 0; i < headIngs.length; i++) {
const elementType = await headIngs[i].evaluate(e => e.tagName);
const typeElement = elementType.toLowerCase();
const headingTxt = await headIngs[i].textContent();
const headingTxtR = headingTxt.replace(/\s/g, ' ').trim()
// console.log('Heading:', headingTxtR)
registry[url].push({
'metaElement': 'heading',
'id': i,
'type': typeElement,
'headingTxt': headingTxtR,
});
}
} catch {
registry[url] = 'No data'
}
// End Heading scrape
// Start scraping images
try {
const images = await page.$$('img')
// console.log('Image:', images)
// allImages = []
for (i = 0; i < images.length; i++) {
let imageItemSrc = await images[i].getAttribute('src')
let imageItemAlt = await images[i].getAttribute('alt')
let imageItemLazy = await images[i].getAttribute('lazy')
// let imageItemSrcTextContent = await images[i].getAttribute('src').textContent();
// console.log('Img:', imageItemSrcTextContent)
registry[url].push({
'metaElement': 'image',
'id': i,
'imageSource': imageItemSrc,
'imageAlt': imageItemAlt || 'No alt',
'imageLazyLoaded': imageItemLazy || 'Not lazy loaded'
})
}
} catch {
console.log('No images on the page')
}
// End image scrape
///Start scraping link elements
try {
const urlHrefs = await page.$$('a, button');
// console.log('urlHrefs:', urlHrefs)
// linkDetails = []
for (let i = 0; i < urlHrefs.length; i++) {
const elementType = await urlHrefs[i].evaluate(e => e.tagName);
const typeElement = elementType.toLowerCase();
const type = 'link'
const href = await urlHrefs[i].getAttribute('href');
const hreftarget = await urlHrefs[i].getAttribute('target');
const hrefrel = await urlHrefs[i].getAttribute('rel');
if (!href) {
href2 = '/#'
} else {
href2 = href
}
const linkTxt = await urlHrefs[i].textContent();
const linkTxtR = linkTxt.replace(/\s/g, ' ').trim()
// console.log('LinkTxt:', linkTxt)
registry[url].push({
'metaElement': type,
'type': typeElement,
'id': i,
'linkTxt': linkTxtR,
'linkUrl': href2,
'hrefTarget': hreftarget,
'hrefRel': hrefrel
});
}
} catch {
console.log('No links on the page')
}
// End scrape links
queue.pop();
console.log("queue lenght", queue.length)
const hrefs = await page.$$eval('a', (anchors) => anchors.map((link) => (link).href));
console.log('HREFS ', hrefs)
// console.log(typeof hrefs) // = object
//// Specify a filter. Use startsWith (website) for scraping all urls found.
//// Use ('https://domain.com/url/filter/folder') to filter on urls with specific path.
//// Scope the scraping to whole domain or specific folders:
const filteredHrefs = hrefs.filter(
// (href) => href.startsWith('http://books.toscrape.com/catalogue/category/books/') && registry[href] === undefined && !href.endsWith('.pdf') && !href.includes('#') && !href.includes('?') && !href.includes('@') && !href.includes('tel:') && !href.includes('.ashx'))
(href) => href.startsWith('https://../portfolio/') && registry[href] === undefined && !href.endsWith('.pdf') && !href.includes('#') && !href.includes('?') && !href.includes('@') && !href.includes('tel:') && !href.includes('.ashx'))
// (href) => href.startsWith('https://www..nl/') && registry[href] === undefined && !href.endsWith('.pdf') && !href.includes('#') && !href.includes('?') && !href.includes('@') && !href.includes('tel:') && !href.includes('.ashx'))
// (href) => href.startsWith('https://www..nl/') && registry[href] === undefined && !href.endsWith('.pdf') && !href.includes('#') && !href.includes('?') && !href.includes('@') && !href.includes('tel:'))
// (href) => href.startsWith('https://.com/') && registry[href] === undefined && !href.endsWith('.pdf') && !href.includes('#') && !href.includes('?'))
// (href) => href.startsWith('https://.app/portfolio/') && registry[href] === undefined && !href.endsWith('.pdf') && !href.includes('#') && !href.includes('?'))
// hrefs.every(str => str.startsWith(website)));
// (href) => href.every(str => str.startsWith(website)) && registry[href] === undefined)
const uniqueHrefs = [...new Set(filteredHrefs)]
queue.push(...uniqueHrefs)
queue = [...new Set(queue)];
}
var end = new Date() - startTime
// console.info('Execution time: %dms', end)
const secondsDuration = end / 1000
console.info(` Scraped: ${addCount} pages in ${secondsDuration} seconds....`)
return res.status(200).send(registry)
} catch (e) {
console.log(e);
res.status(500).send("Something broke")
}
await page.close()
await browser.close()
})
app.listen(port, () => {
console.log(`app running on Port: ${port}`)
})
SEO audit with Playwright
The script evaluates the:
- page title
- meta data
- headings H1 to H6
- images
- links
Use the results to check if relevant technical SEO data is available. For images if Alt tags are solid, if Lazy loading is set. Check if links have a target and nofollow tag.
Steps:
Create a folder in root directory: ‘/html’
Create an index.html in the /html directory, add following Html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Result of website crawl</title>
<script src="https://cdn.tailwindcss.com"></script>
</head>
<body>
<ul id="all"></ul>
<script>
async function loadNames() {
const response = await fetch('toscrape.json');
const Jsondata = await response.json();
const arr = Object.keys(Jsondata).map((key) => [key, Jsondata[key]]);
console.log('ARR', arr)
for (let i = 0; i < arr.length; i++) {
const list = document.getElementById('all')
var resultUrl = arr[i][1].filter(obj => {
return obj.url
})
console.log('resultUrl i', resultUrl)
for (let b = 0; b < resultUrl.length; b++) {
const urlItem = document.createElement('div')
urlHref = (JSON.stringify(resultUrl[b]))
urlItem.classList = 'bg-blue-800 text-white px-2 py-4'
urlItem.innerText = urlHref
list.appendChild(urlItem)
const metaList = document.createElement('ul')
urlItem.append(metaList)
var resultMeta = arr[i][1].filter(obj => {
return obj.metaElement
})
console.log('RESULT', resultMeta)
for (let a = 0; a < resultMeta.length; a++) {
const listItem = document.createElement('li')
listItem.classList = 'odd:bg-white even:bg-slate-200 py-1 my-1 px-4 text-black'
listItem.innerHTML = (JSON.stringify(resultMeta[a]))
metaList.appendChild(listItem)
}
} // End For ResultUrl
}
}
loadNames();
</script>
</body>
</html>- Create ‘toscrape.json’ in the ‘/html’ directory.
- Run and wait for the crawl to finish. The output will be json formatted code.
- The output is visible after running ‘localhost:1234/crawl?website=https://domaintoscan.com’ and waiting for the scrape to be finished.
- Copy the output in this json file
- Open index.html with Live server
- The index.html will fetch the json data and present the data in structured way
- Results of the scanned website and webpages will be visible.
Partial json…
{
"url": "http://books.toscrape.com/",
"id": 1
},
{
"metaElement": "html-seo-title",
"pageTitle": "\n All products | Books to Scrape - Sandbox\n"
},
{
"metaElement": "heading",
"id": 0,
"type": "h1",
"headingTxt": "All products"
},
{
"metaElement": "image",
"id": 0,
"imageSource": "media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg",
"imageAlt": "A Light in the Attic",
"imageLazyLoaded": "Not lazy loaded"
},
{
"metaElement": "link",
"type": "a",
"id": 2,
"linkTxt": "Books",
"linkUrl": "catalogue/category/books_1/index.html",
"hrefTarget": null,
"hrefRel": null
}Result webscraper for SEO
removed some elements…
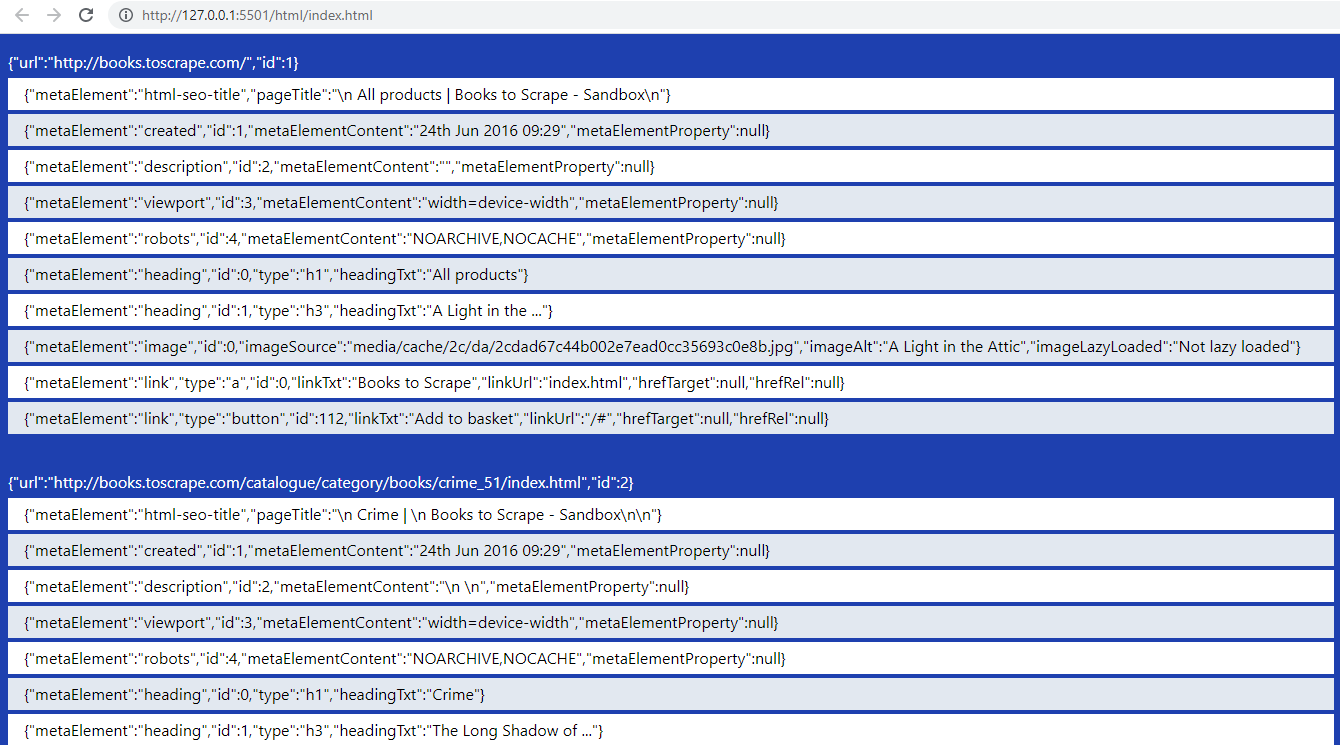
In the script
Books to scrape, scoped to ’http://books.toscrape.com/catalogue/category/books/’
Scraped: 93 pages in 166.077 seconds…
My portfolio
Scraped: 37 pages in 41.154 seconds…
Notes / to do’s
- Better errorhandling. When scraping an element does not succeed values from other pages might be used in the results.
- Some urls end up twice in the queue and in results, caused by urls ending with a slash or not.
- Sometimes the crawler stops after first page, retry and test again. Add or remove trailing slash from start-url, add or remove www from start-url, might give better results.
- This is a webcrawler. Pages which can be found by navigating the website are included. Urls which are not linked from the website (campaign or landingpages for example) are not included in the crawl.
- Add blocking of images loading and block third party javascript to speed up the crawl.
- Use express to create static folder, use it to host index.html.
- Based on: https://www.youtube.com/watch?v=68EO2nT5jYo
Next: Scroll a page with Devtools Protocol
Previous: Screenshot settings in Playwright